K均值聚类算法: 1、适用数据类型:数值型数据。需要数值型数据来进行距离计算,也可以将标称型数据映射为二值型数据再用于距离计算。 2、优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢...
”机器学习实战 K-均值聚类“ 的搜索结果
机器学习-01-一篇万字长文深入了解机器学习必备准备工作:基础知识学习、机器学习工具选择和Python工具包运用
【零基础学机器学习 15】 K-均值聚类( K-means)算法:类型、工作原理及代码实战 https://blog.csdn.net/shangyanaf/article/details/133243206


K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法。
聚类与分类最大的不同在于,分类的目标实现已知,而聚类则不一样。因为其产生的结果与分类相同,而只是类别没有预先定义。 聚类分析试图将相似对象归入同一簇,将不相似对象归到不同簇。相似这一概念取决于所选择的...
经过本章的学习,加深了对k-均值的了解,一个典型的聚类算法,主思想是将样本数据划分为K个簇,使得每个样本点都属于离其最近的簇中心,也就是质点,K-均值算法的优点包括简单、易于实现和计算效率高。然而,该算法...
K-均值聚类算法: 伪代码如下: 创建k个点作为起始轴心 当任意一个点的簇分类分配结果发生改变时 对数据集中的每个数据点 对每个质心 计算质心与数据点之间的距离 将数据点分配到距其最近的簇 对每一个簇,计算簇中...
聚类是一种无监督的学习,它将相似的对象归到...K-均值(K-means) 聚类算法,之所以称之为K-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。 簇识别(cluster identifica...
from numpy import * def loadDataSet(fileName): #general function to parse tab -delimited floats dataMat = [] #assume last column is target value fr = open(fileName) for line in fr.readlines():...
K-均值聚类算法,它可以发现K个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。簇识别概念:假定有一些数据,现在将相似数据归到一起,簇识别会告诉我们这些簇到底都是些什么,聚类与分类的最大不同在于,...
机器学习中有两类的大问题 1.分类 分类是根据一些给定的已知类别标号的样本,训练某种学习机器,使它能够对未知类别的样本进行分类。 supervised learning(监督学习) 2. 聚类 聚类指事先并不知道任何样本的...
主要为大家详细介绍了python机器学习实战之K均值聚类,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
机器学习算法k-均值聚类之c++实现(不调用外源库)

缺点,K-均值聚类中簇的数目k是用户预先定义的,而用户并不能提前预知k的选择是否正确。创建矩阵存储数据集中的每一个点的簇分配结果以及平方误差,然后计算整个数据集的质心,使用列表保留所有的质心。我们可以很...

这一章开始聚类算法的总结,聚类算法是无监督学习的一种 ...所谓k均值聚类,就是分为k个簇,也就是k个分类 目录算法描述优缺点一般流程算法伪代码适用后处理提高聚类性能二分k-均值算法伪代码一个栗子...
K-均值聚类学习思考
标签: K均值聚类
简述:k-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至...


此文为《机器学习实战》《机器学习》学习笔记 一、聚类 在无监督学习中,学习的样本在训练之前无类别标记。聚类方法作为重要的无监督学习方法,学习的过程就是要将这些样本根据某特性的相似性来进行划分,相似性大...
K均值(K-means)是一种基于距离度量的聚类算法,其主要思想是将数据集划分为k个不同的簇,每个簇代表一个相似度较高的数据组。该算法通过迭代优化来最小化所有数据点与其所属簇的欧氏距离之和,从而找到最佳的簇...
《机器学习实战》之K-均值聚类算法的python实现最近的项目是关于“基于数据挖掘的电路故障分析”,项目基本上都是师兄们在做,我只是在研究关于项目中用到的如下几种算法:二分均值聚类、最近邻分类、基于规则的分类...
[1] 机器学习实战之K-Means算法[2] 算法杂货铺——k均值聚类(K-means)[3] 深入理解K-Means聚类算法[4] K-means聚类算法的三种改进(K-means++,ISODATA,Kernel K-means)介绍与对比[5] 机器学习(二)——K-均值聚...

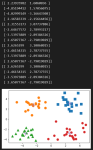
k 均值聚类 1.引入依赖 import numpy as np import matplotlib.pyplot as plt # 调用sklearn中的方法直接生成数据 from sklearn.datasets.samples_generator import make_blobs 2.数据加载和预处理 x, y = make_...
推荐文章
- 第十三周 ——项目二 “二叉树排序树中查找的路径”-程序员宅基地
- C语言基础 -- scanf函数的返回值及其应用_c语言ignoring return value-程序员宅基地
- 数字医疗时代的数据安全如何保障?_数字医疗服务保障方案-程序员宅基地
- 确定性随机数发生器测试向量——DRBG-HMAC-SHA1_drbg_nopr_hmac_sha1-程序员宅基地
- Apache Lucene 8.0.0 发布,Java 全文搜索引擎-程序员宅基地
- java趣事_【趣事】Java程序员最年轻,C++程序员最年老-程序员宅基地
- 用什么软件测试内存条稳定,使用内存条检测工具监测内存稳定性,内存条检测工具有哪些...-程序员宅基地
- Harmonyos 自定义下拉列表框(select)_harmonyos 下拉列表-程序员宅基地
- VBA入门到进阶常用知识代码总结44_msofalse-程序员宅基地
- 公司个人年终工作总结【10篇】_csdn 公司 年终终结-程序员宅基地